So far Big Tech has spent almost $200 billion this year on LLM infrastructure with almost nothing to show for it, yet they have all announced increased spending. OpenAI may burn $5 billion this year, reportedly to be all of its cash. OpenAI may burn $5 billion this year, reportedly to be all of its cash. Is this all a misallocation of capital?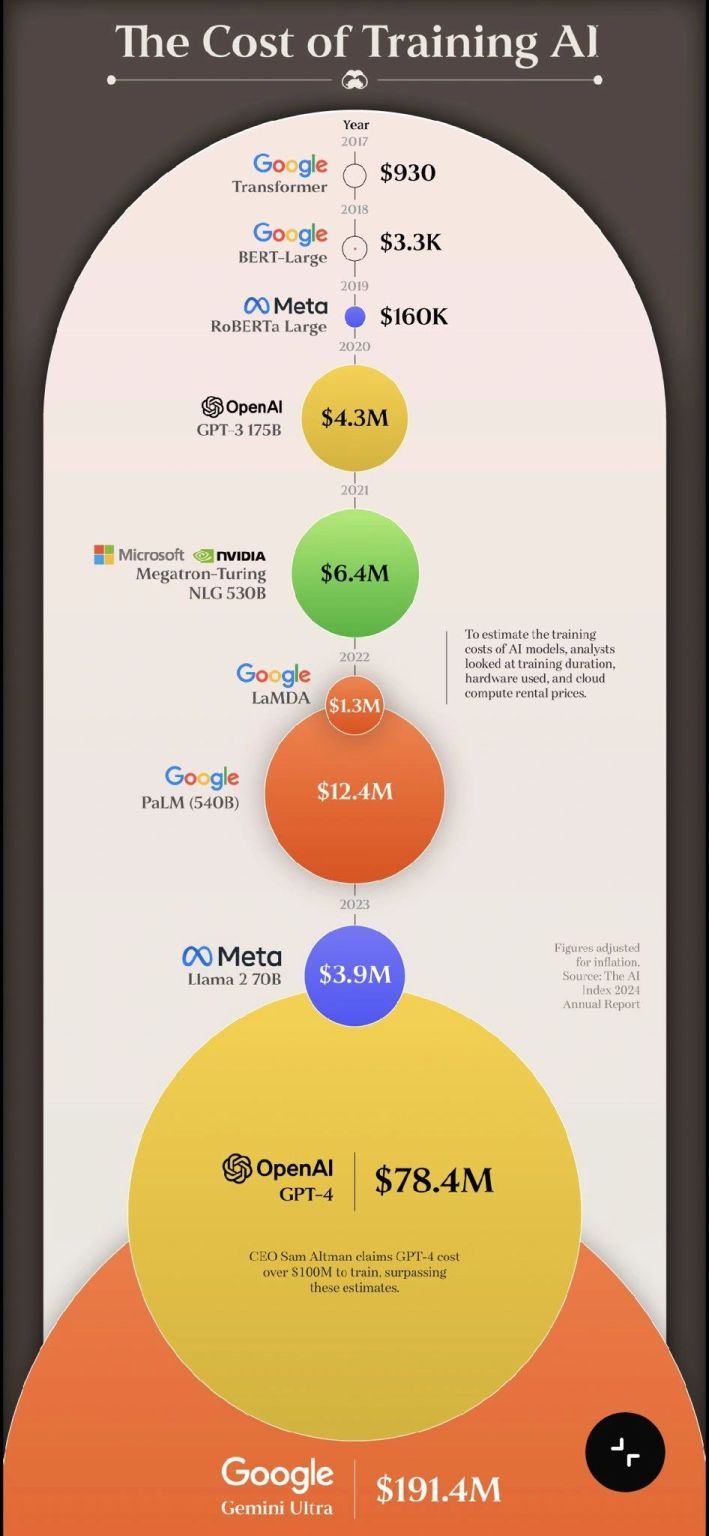
→ Original Transformer Model: $930
→ GPT-3: $4.3M
→ GPT-4: $78.4M
→ Gemini Ultra: $191.4M
Training LLM from scratch costs millions and these numbers are expected to climb even higher with the development of new models. This is why primarily Big Tech companies and well-funded startups can afford to undertake such projects. But why is this the case?
Here’s the explanation:
1️⃣ Data:
→ Curating TBs of data and extensive pre-processing are needed. This involves collecting, cleaning, and organizing data to ensure the model trains on high-quality information. This task is resource-intensive, requiring significant time and manpower.
2️⃣ AI Talent and Skills:
→ Developing LLMs requires top researchers, with compensation at companies like OpenAI rumored up to $10M. A team of machine learning, data science, and linguistic experts is essential. They design neural networks, manage training processes, and assess performance. The significant cost of hiring and retaining this skilled workforce is crucial.
3️⃣ AI Computing Power:
→ Training and developing LLM is incredibly expensive due to the vast computational resources required, with models like GPT-4 needing thousands of GPUs running for months (!). This extensive use of GPUs, combined with the need for continuous fine-tuning and experimentation, significantly drives up both the hardware and operational costs.
The real problem is that current LLM cannot unlearn or correct themselves. They are stuck in data sets they were trained with. This is the main reason why current AI is a misleading buzzword.
Human intelligence allows to correct mistakes. We can reconsider, correct. relearn, unlearn, retrain. You cannot convince AI that its output is wrong. It won’t understand. It keeps hallucinating.
The current approach to train with more data won’t improve the situation. It will just introduce new flaws at increased costs, without the ability to correct / unlearn.
The current concepts of LLM cannot deliver what is promised in slide decks. From what we see in current models, unlearning or retraining of specific aspects seems not possible because changes of specific data points in the model would have unpredictable impacts on the entire model. Means, you might fix some flaws (like RAG tries to do) and introduce new ones (which RAG cannot fully prevent).
From what we can see, the overall current concept is not capable to solve this. Bigger models are not the solution. A complete new approach is needed. The question is who would invest to start from scratch when the hype ends. The comparison with dot-com is also not valid. The creation of intelligence on earth took billions of years. It needed lots of bubbles.
This is a similar problem with innovation for innovation’s sake. Lots of companies innovate a lot and build nothing. Replacing poor outcomes with better ones by a form of innovation should be the goal. Right now AI appears to be more form, less substance; more quantity, less quality. All trying to hit generic “mass market” success.
